Lecture 5
Multivariate Visualization
A picture is worth a thousand words. This may be especially true in statistics. While plotting univariate or even bivariate data is not too difficult, and we can learn much from such plots, multivariate data is much more difficult to visualize effectively. We often have a number of variables in a data set and we want to learn as much as we can about their relationships. We explore some techniques here.
One reason why many data analysts use R is because R can create graphics that are both informative and visually appealing without too much effort or time (if you use the right packages and know what you are doing). For the next two lectures, we will explore methods for visualizing multivariate data using three dominant plotting tools: base R plotting, plotting using the lattice package, and plotting using the ggplot2 package. This first lecture discusses base R plotting.
Base R Plotting
R comes built in with functions for plotting, the primary one being the plot() function, which we have seen before. It is a generic function that will often pick the right plot for the object passed to it. That said, we do have control over how to make a plot using base R.
A scatterplot plots each data point as an ordered \((x,y)\) pair, with \(x\) being the value of the variable corresponding to \(x\) for each data point, and \(y\) the value for the corresponding \(y\) variable. Thus scatterplots are useful for visualizing bivariate data.
We can make scatterplots using base R with plot(x, y), where x and y are numeric vectors containing the x and y coordinates to plot, respectively. The plot created by default will be a scatter plot, though there are many parameters for plot() that will change not only whether a scatterplot is drawn but other characteristics of the resulting plot, such as the extent of the axes, the character of the points, axis labels, and many others.
Suppose we wished to compare the sepal length of iris flowers to the petal length of iris flowers in the iris data set. We could do so in base R with the following:
plot(iris$Sepal.Length, iris$Sepal.Width)
This plot gives us some basic information about these variables, but a lot is not shown. In particular, we know that there are three species of iris included in the iris data set, and we would like to display this information on the chart. We could do so using the following:
with(iris,
# First, the scatter plot
plot(Sepal.Length, Sepal.Width,
# Make the color depend on the species
col = as.numeric(Species),
# Also make the character depend on the species
pch = as.numeric(Species),
# Some labels to make the plot more informative
xlab = "Length", ylab = "Width", main = "Dimensions of the sepal of iris flowers"
)
)
# Add a legend to the plot
legend(
# The first two arguments are the coordinates of the legend on the plot
6.1, 4.4,
# The next argument is the species of flower to label
c("setosa", "versicolor", "virginica"),
# The colors used for encoding
col = 1:3,
# The character used for encoding
pch = 1:3
)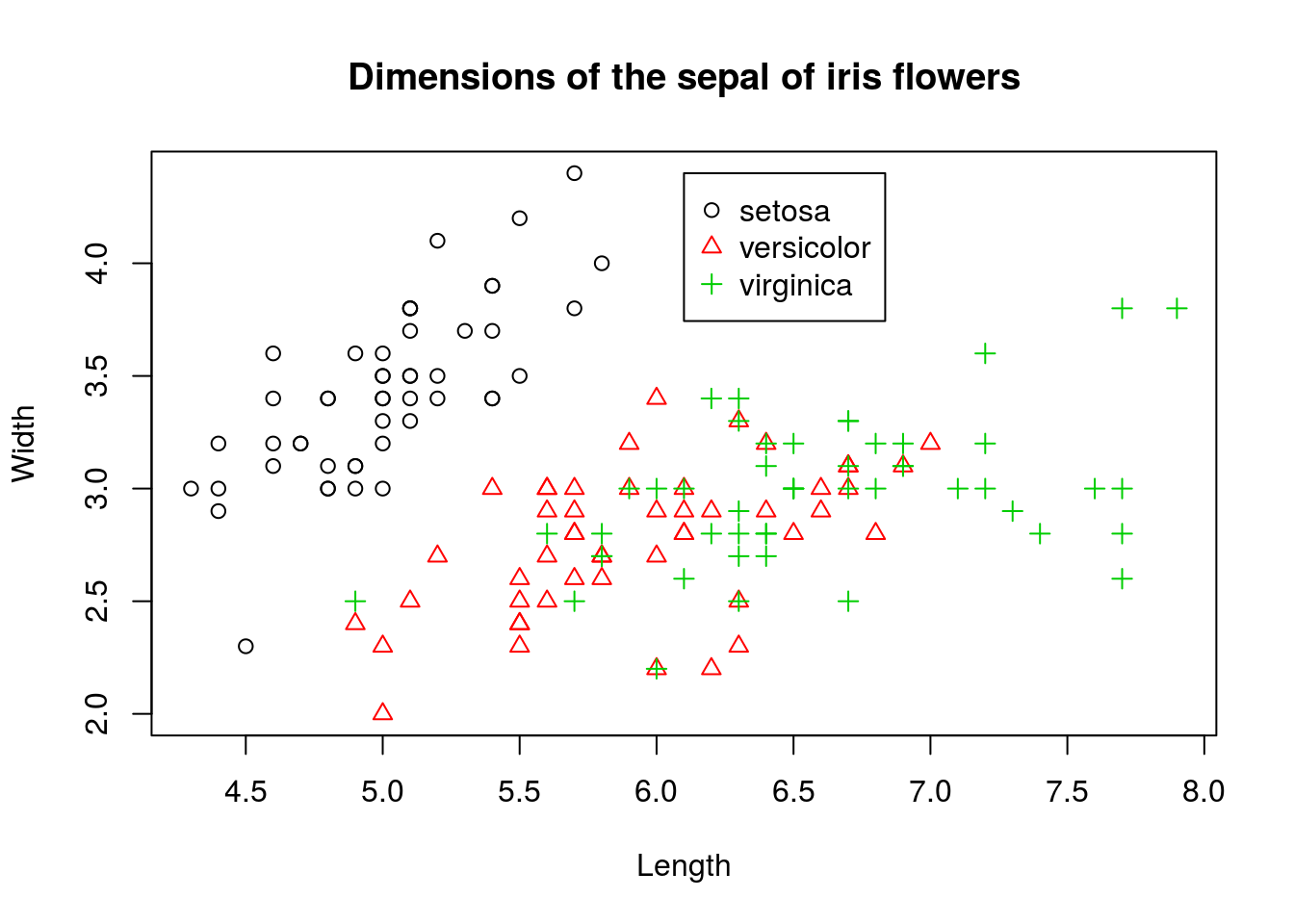
We kept the scatterplot, but distinguished different species by color. To further differentiate points, we also changed the shape of the points and made them depend on species. In other words, we doubly encoded the species information in both the shape and color of the points in the scatterplot.
Suppose we don’t want all the species on the same plot. Versicolor and virginica flowers are intermixed, making them difficult to distinguish in the plot. We may try to create three plots side-by-side by changing the settings of a function called par(), which controls how plots are created. The following code does so:
width_range <- range(iris$Sepal.Width)
length_range <- range(iris$Sepal.Length)
# Manually split into three datasets
iris_setosa <- subset(iris, subset = Species == "setosa")
iris_versicolor <- subset(iris, subset = Species == "versicolor")
iris_virginica <- subset(iris, subset = Species == "virginica")
# The par function controls plotting parameters like margin size, borders,
# and many others. For this purpose, we would like to use margin to allow us
# to plot multiple plots, specifically in a 1x3 grid. The parameter we can
# set with par to control this is mfrow, which we set with a length 2 vector
# with the first coordinate being the number of rows, and the second
# coordinate being the number of columns. First, save the current par
# settings:
old_par <- par()
# Now, change the settings
par(mfrow = c(1, 3))
# After setting this way, we call plots as usual, but when they are made
# they will be added to the 1x3 graphic left-to-right, top-to-bottom. I
# also use formula notation to create the plot here. To make a (x,y) plot,
# use y ~ x.
plot(Sepal.Width ~ Sepal.Length, data = iris_setosa, ylim = width_range, xlim = length_range,
main = "setosa")
plot(Sepal.Width ~ Sepal.Length, data = iris_versicolor, ylim = width_range,
xlim = length_range, main = "versicolor")
plot(Sepal.Width ~ Sepal.Length, data = iris_virginica, ylim = width_range,
xlim = length_range, main = "virginica")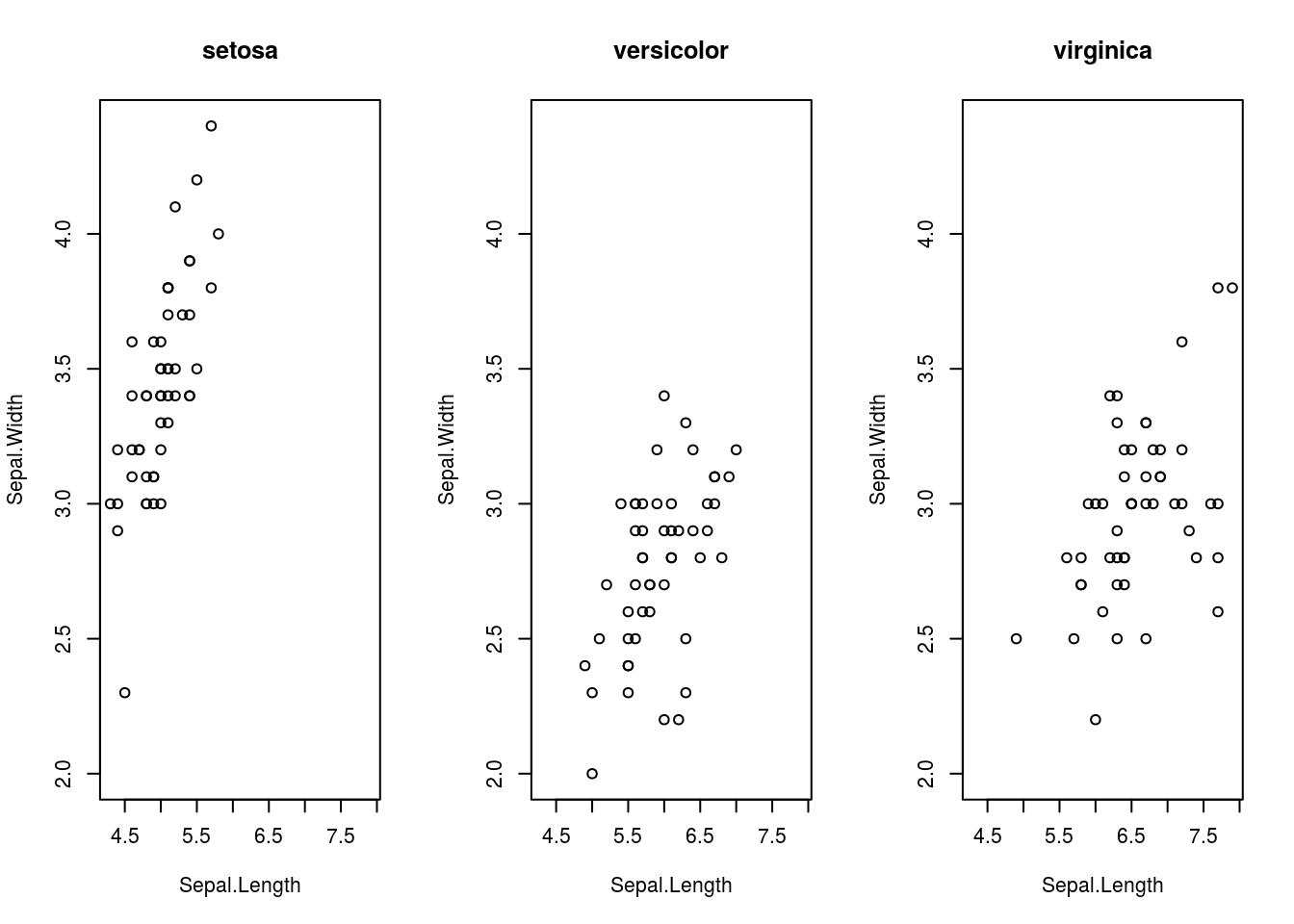
# You should reset par to its original settings once done, or you will
# continue to get plots using these settings, which may not be what you
# want.
par(old_par)## Warning in par(old_par): graphical parameter "cin" cannot be set## Warning in par(old_par): graphical parameter "cra" cannot be set## Warning in par(old_par): graphical parameter "csi" cannot be set## Warning in par(old_par): graphical parameter "cxy" cannot be set## Warning in par(old_par): graphical parameter "din" cannot be set## Warning in par(old_par): graphical parameter "page" cannot be setNow, suppose that a third variable we wish to plot is numerical rather than categorical. We may use a bubbleplot to do so, where we create a scatterplot but each point in the scatterplot is a circle with area representing the value of a third variable. (Note that the third variable must be encoded by area, not diameter! This is because people percieve area, not diameter, and using diameter to encode information rather than area will create plots that are confusing and misleading.) We can create a bubble chart in R by making the cex parameter in plot(), which controls the size of points, dependant on one of the variables in the data set.
The following plot is a bubbleplot that shows states average teacher salary, average total SAT score, and encodes the percentage of SAT takers as the area of the bubbles.
# The SAT data is in UsingR
library(UsingR)
plot(total ~ salary, data = SAT,
# filled circles
pch = 16,
# rgb is a function for creating colors via RGB values. The alpha parameter controls transparency. I make the circles semi-transparent.
col=rgb(red = 0, green = 0, blue = 0, alpha = 0.250),
# cex controls the size (length) of the points. The following makes the points' area dependant on the perc variable in SAT, with division by 10 just to keep sizes under control
cex = sqrt(perc/10))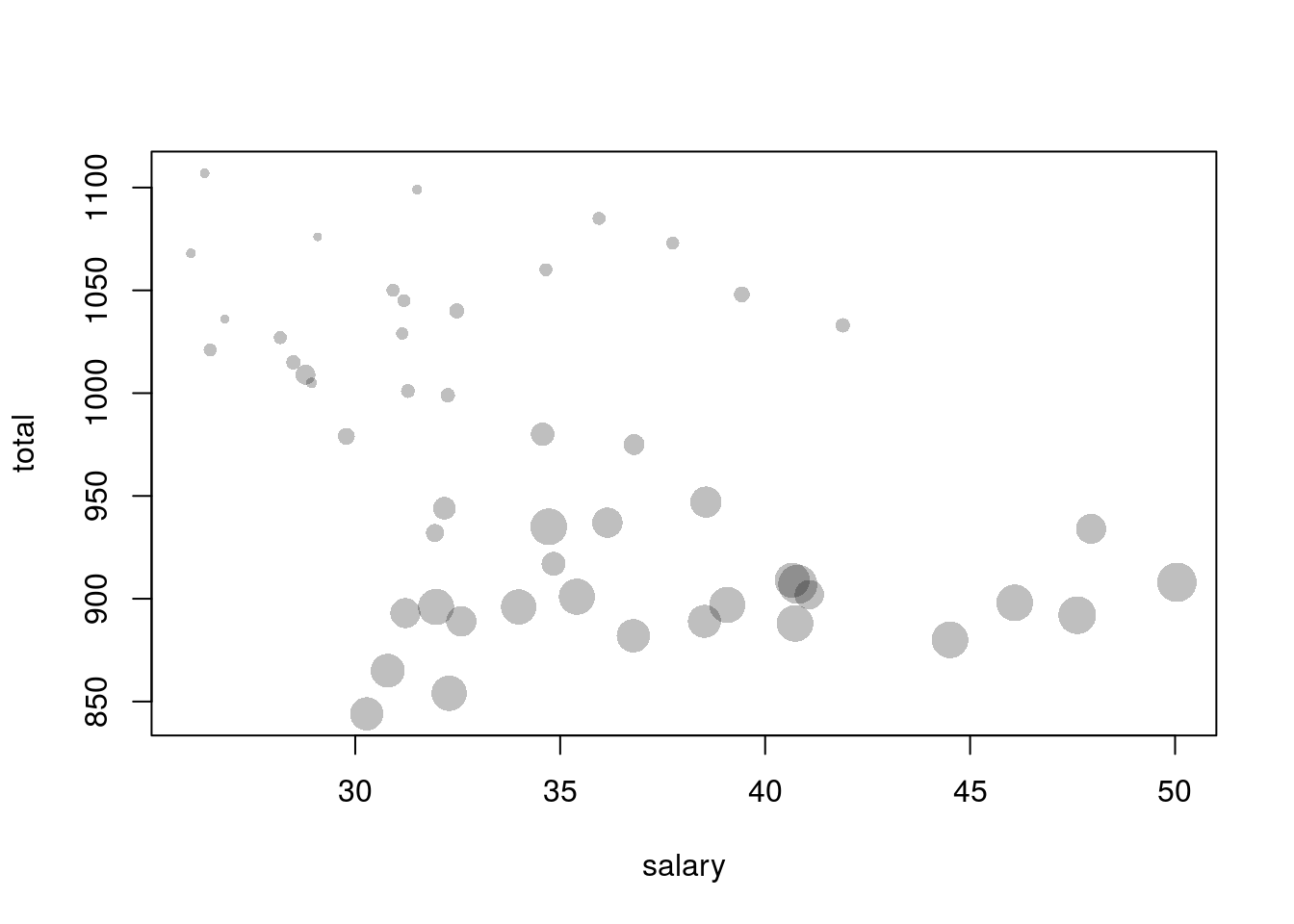
So far, we have seen ways to visualize three variables together, basing our graphics on scatterplots. What about data sets with more than three variables?
A scatterplot matrix creates multiple scatterplots in a grid (matrix), each showing a different combination of variables. The variables become the rows and columns of the matrix, and the plot in a particular row and column of the matrix represents a particular combination of the variables.
The pairs() function will create scatterplot matrices. The first argument passed to it is a data frame containing the data to be plotted, and other parameters can change details about how the plot is made. I create a scatterplot matrix for the iris dataset below.
pairs(iris[c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width")],
# Make color depend on species
col = iris$Species)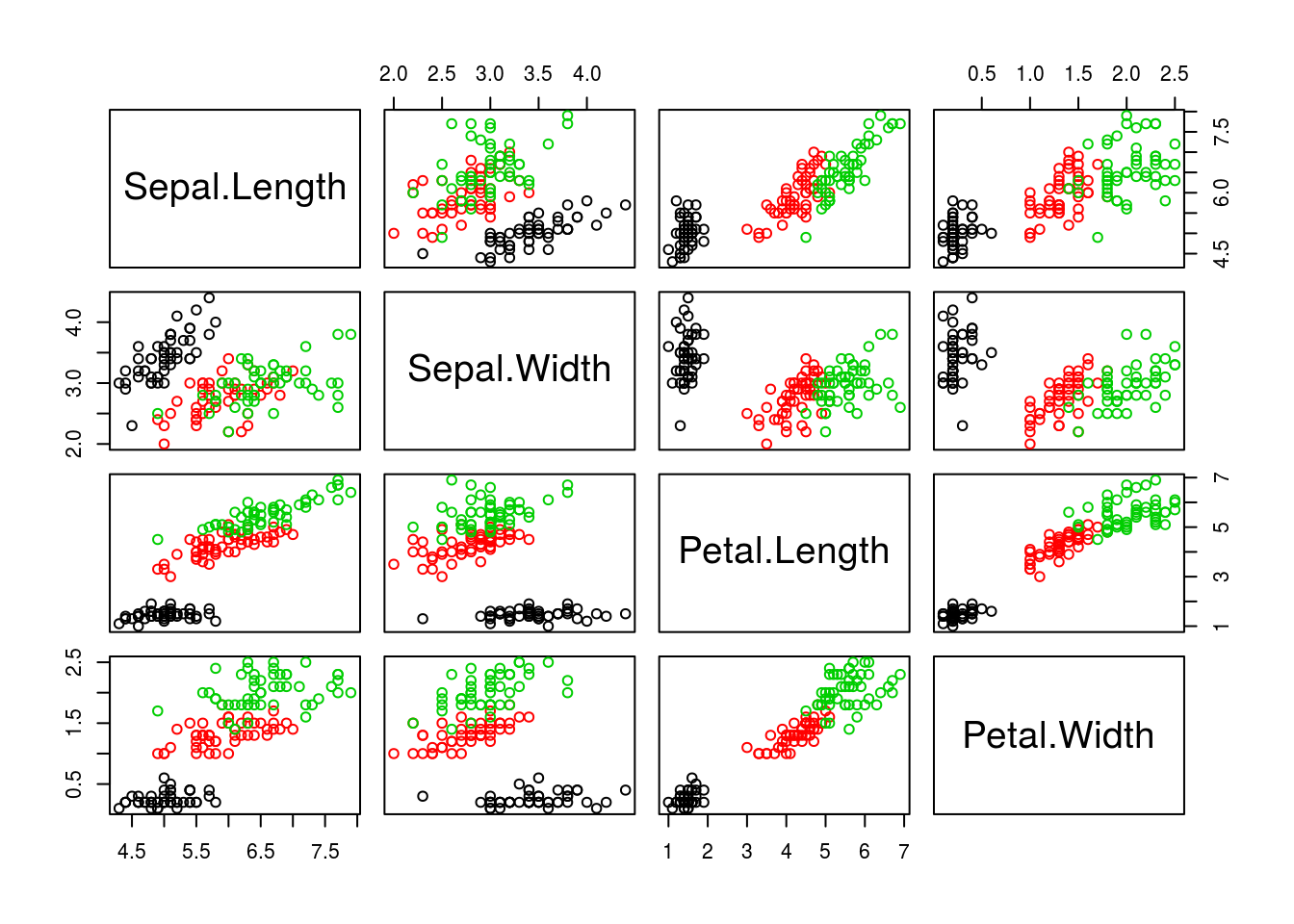
Another way to visualize multivariate data is with a parallel coordinate plot. This plot will display variables as vertical axis lines and data points as lines connecting the axes. The point where a data point line intersects an axis represents the value of that variable for that data point.
The parcoord() function (in the MASS package) creates parallel coordinate plots. The first argument is a data frame containing the data to be plotted, and other parameters control other features of the resulting plot. An example for the iris data is shown below.
library(MASS)
parcoord(iris[c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width")],
col = iris$Species)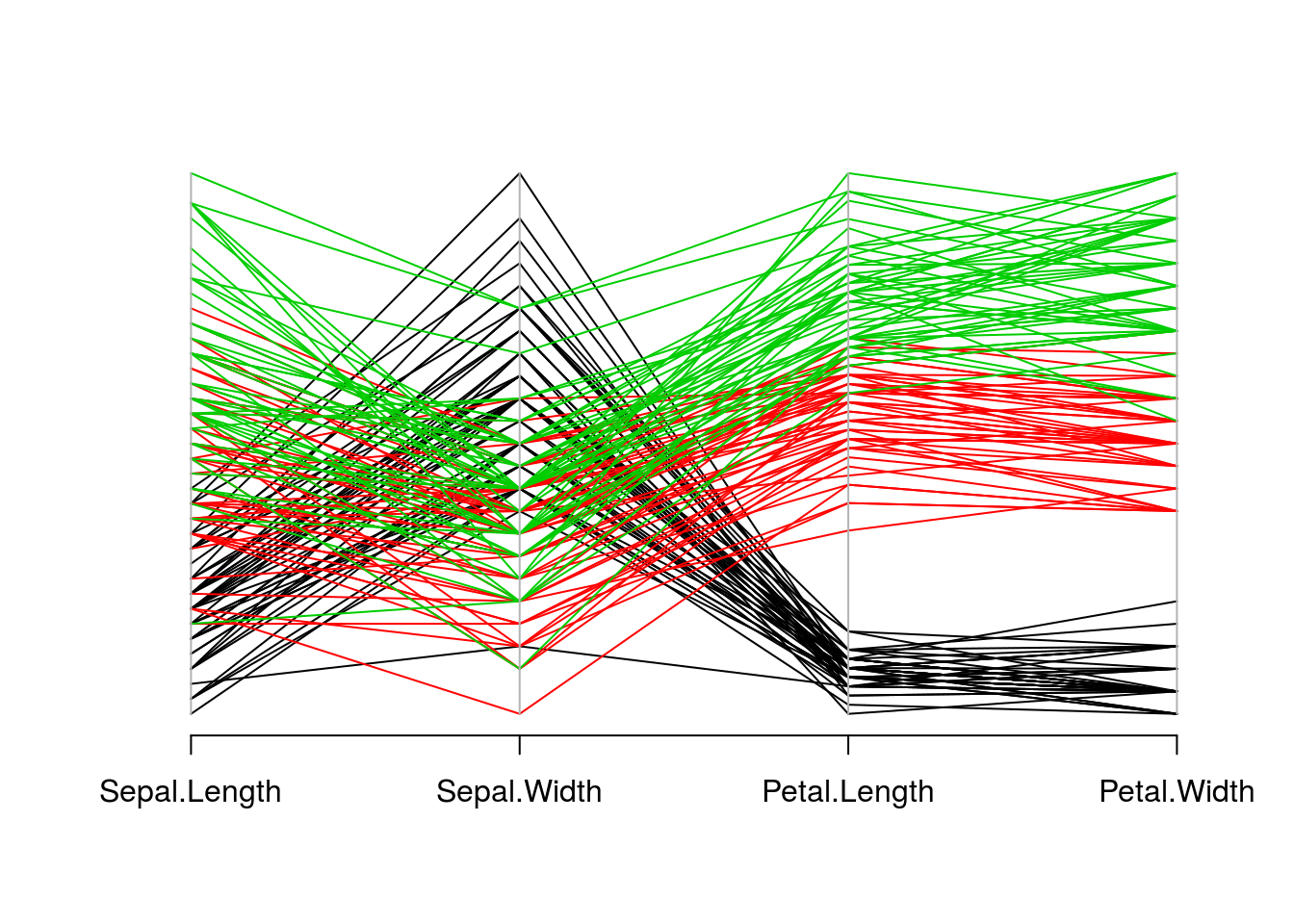
A heatmap is a matrix where the rows are data points, columns are variables, and in each cell of the matrix the value of a variable for an observation is represented in color. The hue or intensity of the color depends on the value of the variable.
The heatmap() function will create heatmaps in R. The first argument is the numeric matrix with the data to plot. I create a heatmap for the mtcars data set below.
heatmap(as.matrix(mtcars), Rowv = NA, Colv = NA)
# This is not a useful plot; the heatmap function thinks that all the
# observations are in the same units. What I will do is create a numeric
# matrix with the standardized value of each variable, where I subtract the
# mean of each variable from each observation, then divide by the standard
# deviation.
plotmat <- sapply(mtcars, scale)
rownames(plotmat) <- rownames(mtcars)
heatmap(plotmat, Rowv = NA, Colv = NA)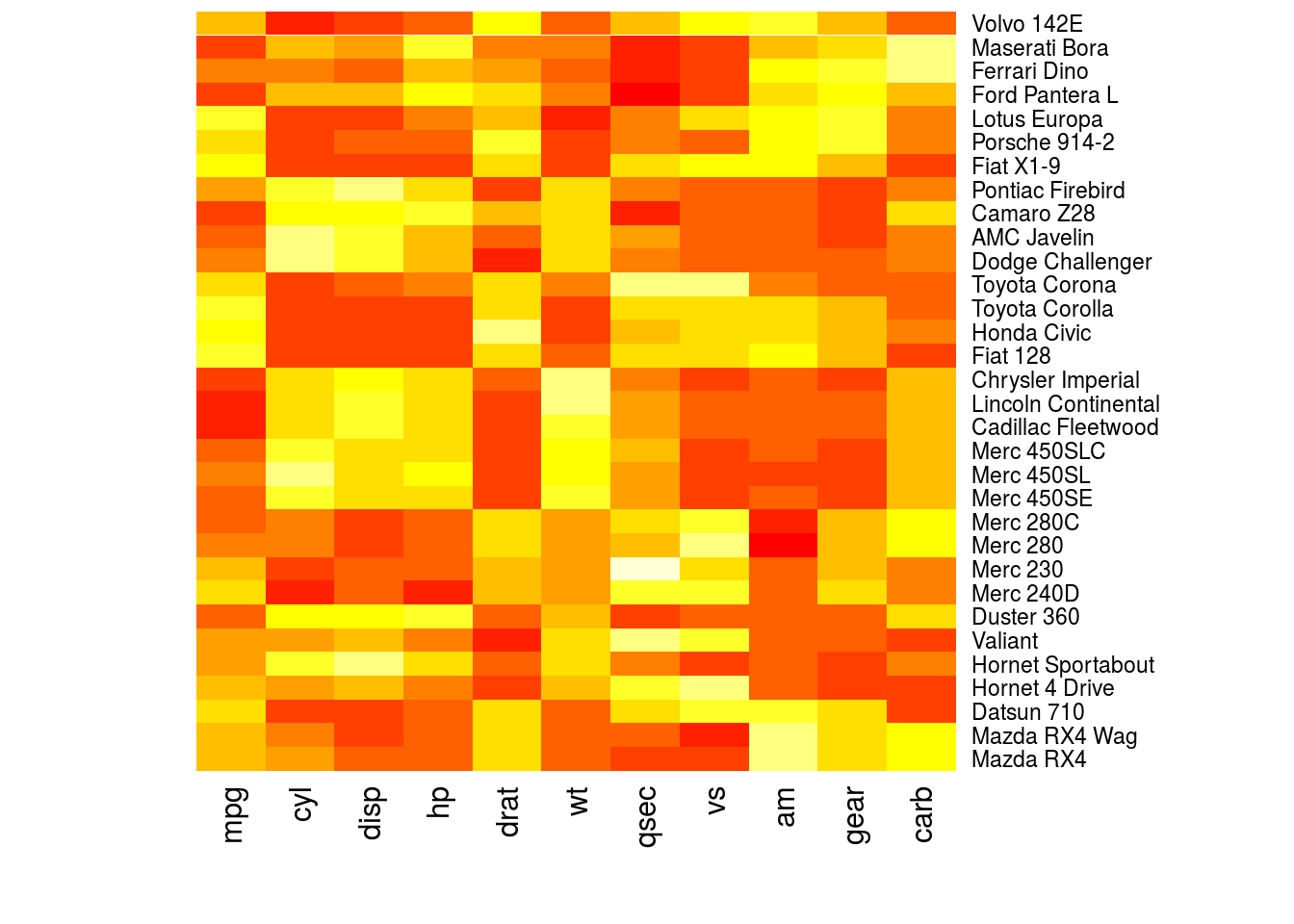
Plotting with base R has the advantage that all installations of R include the base R systems. All other plotting implementations are best seen as useful user interfaces for the existing base R system (particularly a plotting system called grid, which is the basis of lattice and ggplot2). Additionally, plot() is a generic function that can be programmed to create the most useful plot for the object passed to it.
That said, many data analysts prefer to use packages such as lattice or ggplot2 for much of their graphical work, avoiding base R plotting. Unless there is a convenience function or plot() method for whatever plot you wish to make, it can be unacceptably tedious to make plots using only base R, especially if they are complex plots. The plot we created for the second iris scatterplot, for example, needed a legend, which we created manually in a manner both tedious and not very robust to changes in the plot or underlying data.